技能训练
(1)K-means算法的核心内容是什么?
(2)质心迁移的标准是什么?
(3)K值的选择方法有哪些?
(4)为什么要使用正则项?
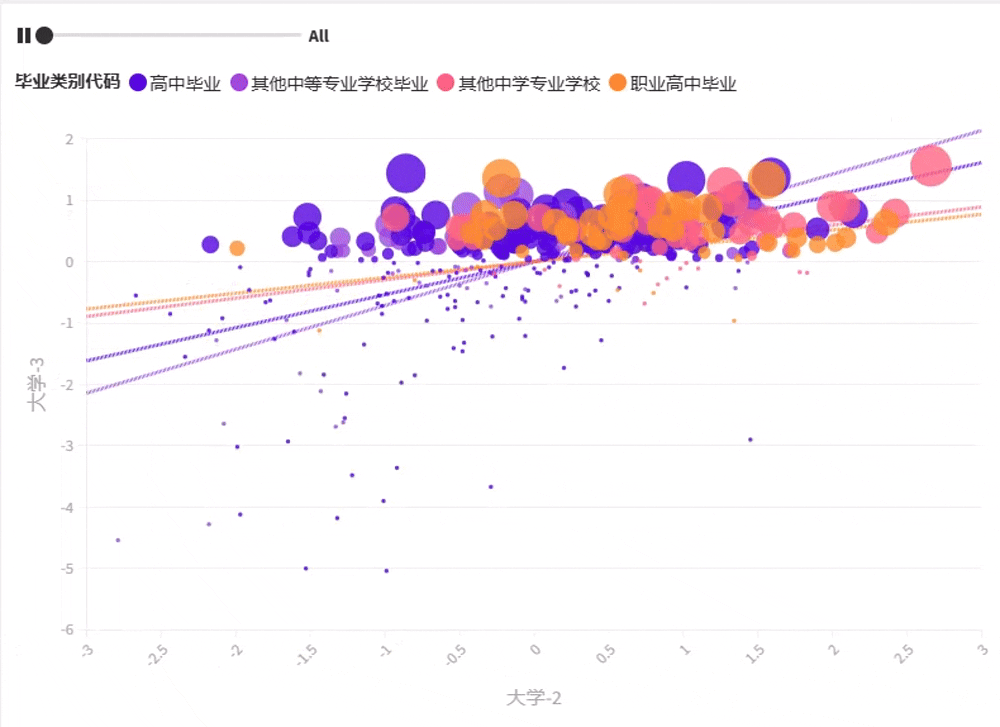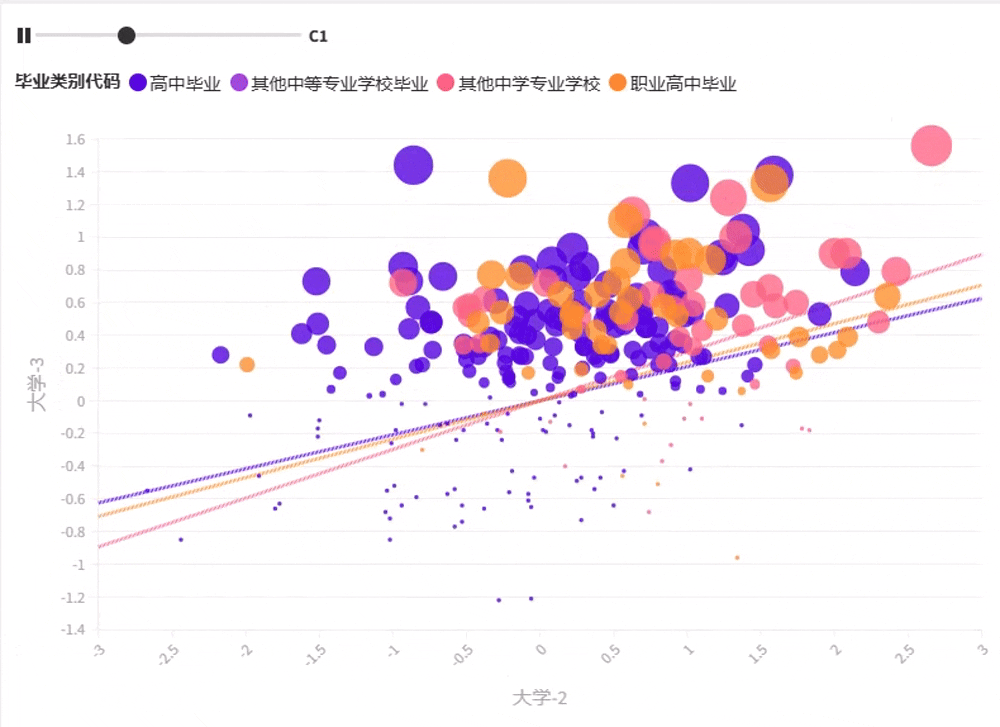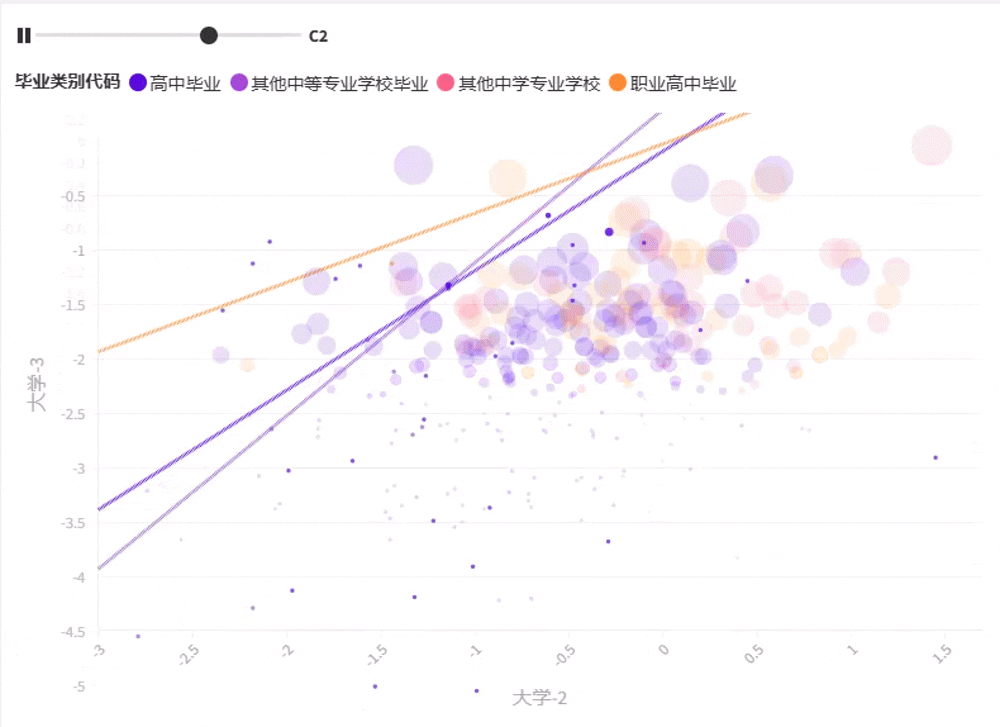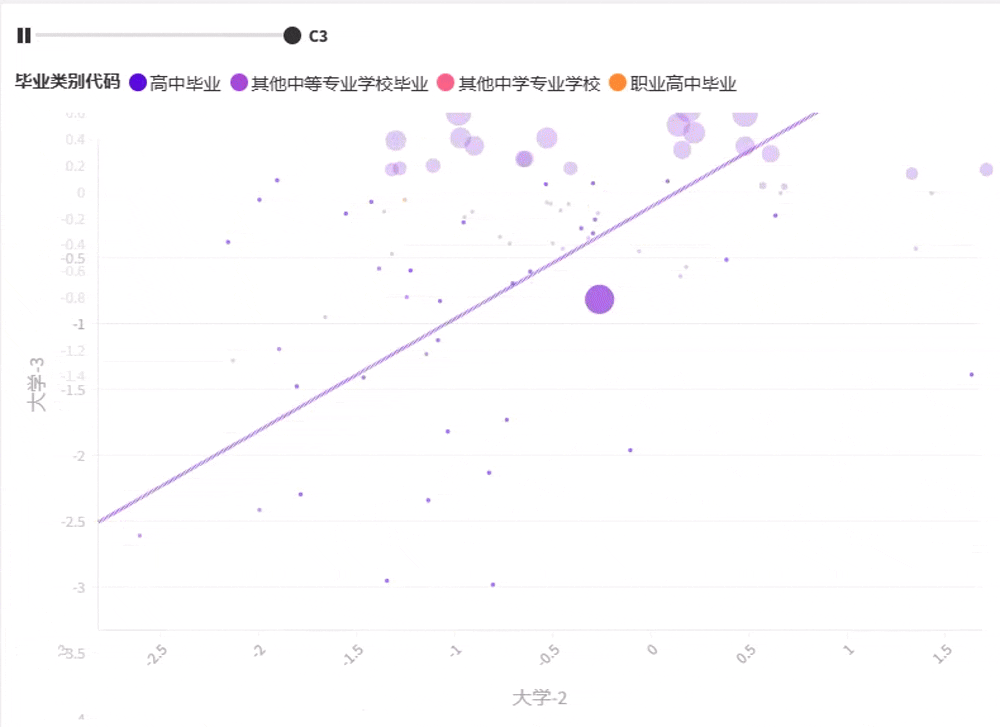
数据集说明:数据集包含了某大学 2022—2022 年三年学生的教学大数据,其中包括学生的类型信息(性别、毕业类别、科类三个信息)及成绩信息(高中毕业、大学-1、大学-2、大学-3)。
类别信息为目录型特征变量,呈现如下:
性别:男、女;
毕业类别:高中毕业、职业高中毕业、其他中等专业学校毕业。
科类:理工、文史、中职对口、五年一贯制转段。
③作业内容。
作业包括两部分:数据集的归一化处理和聚类分析, 将数据集按不同特征变量组合进行 K 近邻分析,并形成群组对照。
a. 归一化处理方法。 采用 Z-score 标准化处理方法,对序列进行变换:
则新序列的均值为 0,而方差为 1,且无量纲。
按以上要求,将学生成绩按类型归一化。
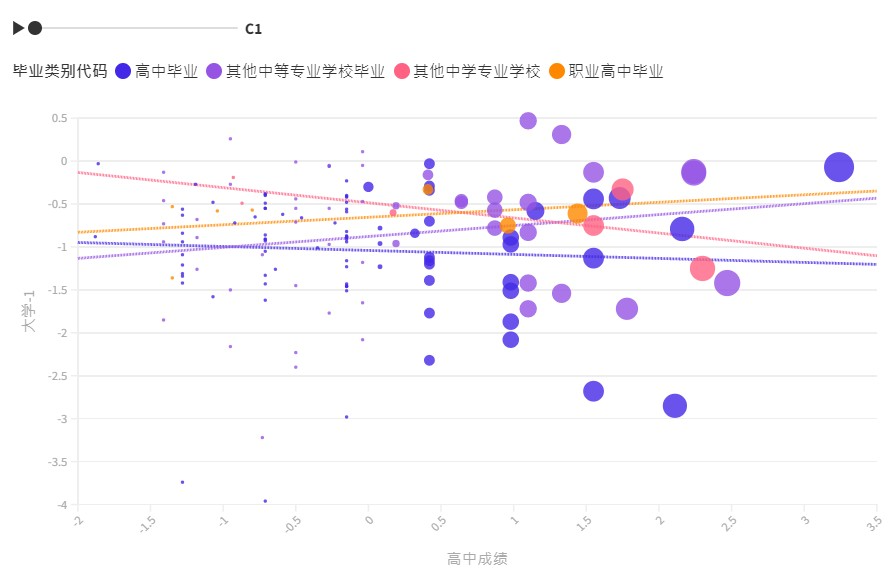
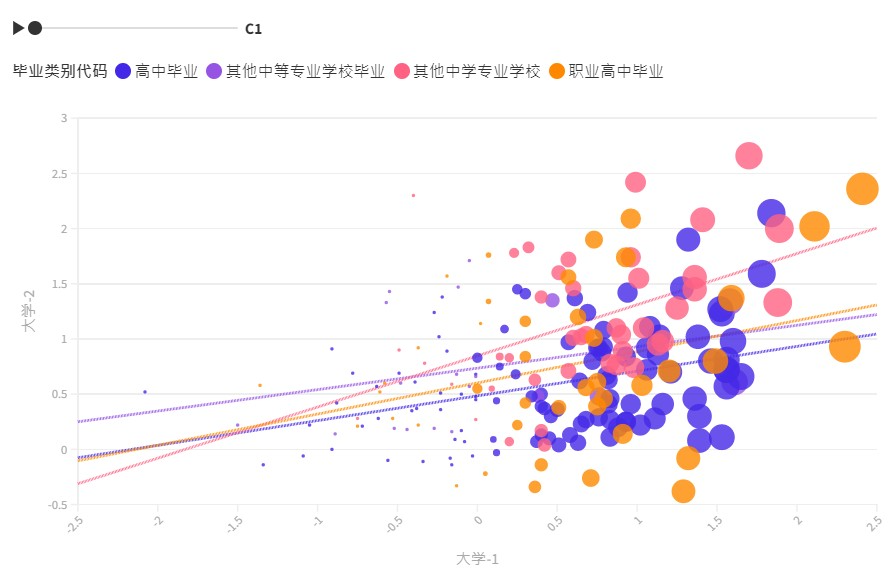
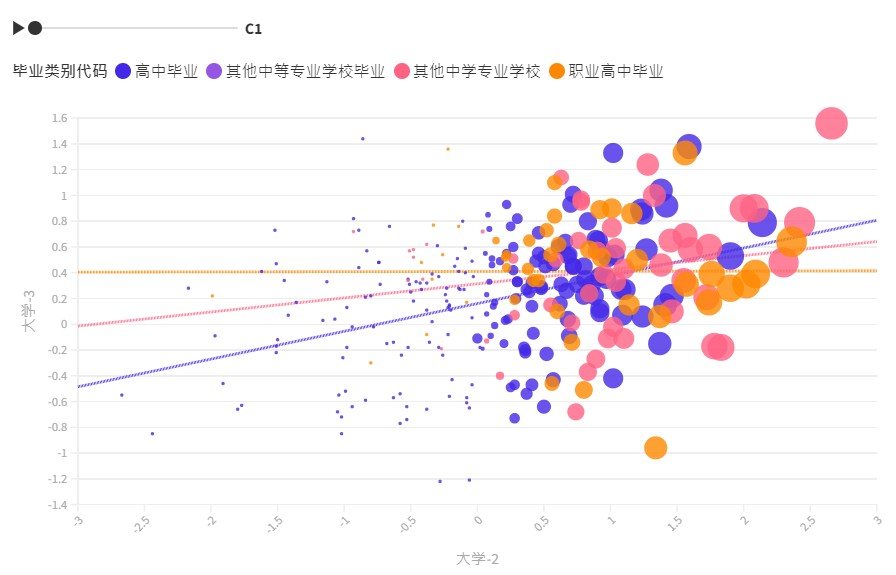
b. 聚类分析。学生需构建处理流程图,并保存轮廓系数表,
将最优 K 聚类保存并生成图形,如图2-2-16~图 2-2-18 所示 。
。
。