あみだくじたちは「群」になれるのか?
あみだくじを作ろう!
あみだくじをつないでも、あみだくじ。
123はどう動く?
このワークシートはMath by Codeの一部です。
<たて線3本アミダ>
「群」groupというのは、ただの群れとか集まりというものではなく、ルールに適合する群れだ。
2項演算(2つのoperandに対する演算operator)を集まりに対して定めたとき、
・2項演算がそのグループの要素にとどまる。はみ出さない調和のとれた動き。閉じている。closure
・結合法則が成り立つ。abc=a(bc)=(ab)c。みんな仲良くくっつける。associative
・1つの単位元・零元(何もしない元identity)がある。停止も運動の1種。
・どの要素にも逆元・反元(演算をもどす元)がペアで存在するinversible。逆の動きも仲間だ。
これらがOKならば、何でも「群」と言える。
アミダは群になるだどうか?
まず、たて線が3本で調べてみよう。
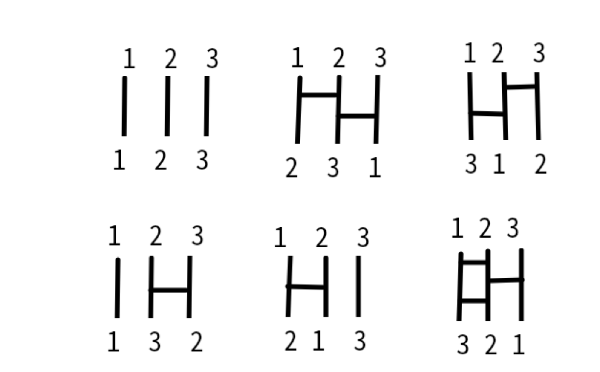
1.3本アミダ
あみだくじのように線をひいて、位置を変えることを置換という。
番号を入れ替える操作をしているとも言えるね。
タテ線に乗っかって下にきた場所に上の番号がかいてある。
だから、下の番号だけ書き出すと、123,231,312,132,213,321となり
123の3つの番号の順列数3!=6通りの入れ替えがすべてできていることがわかるね。
<1段目の3つの置換>
(1段目の左図)
この置換はヨコ線が0本だから、何もしない。だから、これが単位元、0元だね。何もしないのも置換。
あみだくじでヨコ線を1本ひくと、隣接要素の交換を表す。2要素の交換のことを互換という。
1段目の3本アミダはヨコ線が0か2本なので互換数が偶数。偶数の互換なので偶置換とよぼう。
2段目の3つはヨコ線が1か3本なので奇置換とよぼう。
1と2をつなぐヨコ線は互換を引き起こす。これを、(12)とかこう。
2と3をつなぐヨコ線は(23)とかこう。3と1をつなぐヨコ線は(31)とかこう。
合成関数g*f(x)がxに対してfが先で、gを次にすることを表した。
(1段目の中図)
このアミダは、上に(12)、下に(23)なので、この合成は右先左後の表記で、(23)*(12)となる。
1→2の終点2が、2→3の始点2とつながり、1→2→3の移動がおきて1→3となる。
左から1番は左から3番の位置にたどりつき、2→1、3→2の行き先変更は合成されない。
とかくと、番号の動きが見やすいね。途中の↓を省略してよい。
(1段目の右図)
このアミダは、上に(23)、下に(12)、なので、この合成操作の表記は(12)*(23)となる。
3→2の終点2が、2→1の始点2とつながり、3→2→1の移動がおきて3→1となる。
1→2、2→3の行き先変更は合成されない。
だから、
2.あみだくじは互換か巡回置換であらわせる
1段目の右図の置換
これは、おもしろいね。
1→2, 2→3, 3→1の順繰りにサイクリックに1つずつずらしているように見える。
だから、これを1サイクルを順に(1,2,3)とかき、巡回置換[cyclic permutation]
という名前がついている。直訳しただけの日本語ですなあ。
まあ、順ぐり置き換え、くるっと回すでもいいのだけれど、世間の常識の言葉を使っておこう。
1段目の中図は、さっき見た巡回置換に直せないだろうか?
1→3, 3→2, 2→1 と数字の大小はきれいではないが巡回しているね。(1,3,2)とかけるね。
<2段目の左、中、右の図>
では2段目を左からみよう。
1個目は(23)の互換だ。
2個目は(12)の互換だ。
3個目はヨコ線は上から順に(12)、(23)、(12)だ。合成互換の書き方では(12)*(23)*(12)。
1は(12)で1→2となり、次の(23)で2→3となるから、2でつなぐと、1→3。
2は(12)で2→1となり、最後の(12)で1→2となるから、1をつなぐと、2→2でもとにもどる。
3は(23)で3→2となり、最後の(12)で2→1となるから、2をつなぐと、3→1。
だから、2は変わらず、互換(13)と同じになるね。
3.アミダをつなぐ
<たてにつなぐのが演算>
アミダを区別しやすくするために、名前をつけよう。
1段目は偶置換で、左からe =( ), r=(1,3,2), s= (1,2,3) 。
2段目は奇置換で、左からa=(23),b=(12),c=(13)。
ではこの6要素を九九の表のようにたてとよこにならべよう。
6つ要素どうしの演算結果をかいて表をうめることをイメージしてみよう。
よこに、x={e, r, s, a, b, c}と並べたとき、たてに、y={e, r, s, a, b, c}と並べてうめてみる。
1行目は e*x=x={e, r, s, a, b, c}とそのまま並べるだけ。
2行目はr*x = {r*e, r*r, r*a, r*b,r*c}となるね。
たとえば、r*aはa=(23)の下にr=(1,3,2)をつなぐことになるね。
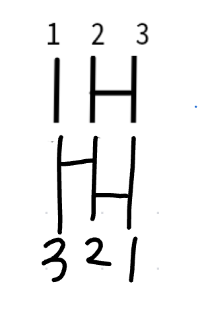
一番下の番号が321の順になったので、あみだくじでは2段目の最後、つまりcと同じになる。
aで2→3、rで3→2となるから、3をつなぐと2→2となるなどして、(13)になることがわかるね。
だから、r*a=cだ。
群の九九表のようなものを群表を呼んだりするけど、群表をかかなくても、
2つのあみだくじをたてにつなげば、1,2,3の番号が入れ替わるだけなので、その演算結果は
6つの要素のどれかと同じになるしかない。
つまり、閉じていることと結合法則は明白なので、これは調べなくても大丈夫だね。
・単位元、つまり、なにもしない置換、ヨコ線のないのが、eであり、1つしかないからOK.
・では逆元をしらべよう。
同じ互換を繰り返すともとに戻るから a*a=e, b*b=e, c*c=eとなるね。
3要素の巡回置換は3回くりかえすともとにもどるから、r*r*r=e, s*s*s=eだ。
rを2回するとsになり、r*r=s。同じようにして、s*s=r。
xの逆元(反元)をx-1とかくと、a-1=a, b-1=b, c-1=c, r-1=s, s-1=r, e-1=eとなるね。
6つの置換にすべて逆が1つずつあるので、逆元もクリアした。
3本アミダを上下につなぐことをあみだくじの演算とすると、
この演算で、アミダは群になっていることがわかったね。
群のコトバでは、3本アミダをS3={e, s, r, a, b, c}を、たてにつなぐことを演算*とすると、
3本アミダ群は<S3, * >とかくことができるね。
質問:3本アミダ群<S3、*>の群表をコードで作成するにはどうしたらよいでしょう。
・巡回置換は(a b c ... z)は働きとしては、辞書{a:b, b:c, ...., z:a}になる。これがami2dic関数。
あみだのリストごと、辞書のリストにして返すamis2dics関数もあると便利だね。
・あみだaの行先を出すami_go関数は、aにないキーkの行先はkのままにする。
・あみだの連結はconL(a,b)関数で、aの行先をキーにしてbの行先にいく連結辞書を作ります。
conR(a,b)関数はbの行先をキーにしてaの行先にいく連結辞書を作ります。
辞書がそのまま返されても視認性が悪いので、巡回置換に名前をつけて識別しやすくしよう。
すべての置換Sと名前をタプルにして返すrotdic(S)関数によって、
要素の名前、集合に含まれる要素の名前、演算結果の要素の名前を返すために、
関数、name(a)、names(H)、aH(a,H)、Ha(H,a)を作ります。
これだけ、準備しておけば、群表を作ることはできます。
タイトルをつけるために、naming(S)をprintします。
そのあと、上につけるアミダをitemとして、name(item)、amiSetR(S,item)をprintすると、
右にかける要素ごとに、Sがどうなるかをリスト表示できます。
このitemをSの要素から順に選んで実行すれば、群表ができますね。
#[IN]Python==================================================
#巡回リストamiを辞書にする。(例)a=[1,2,3] → dic={1:2,2:3,3:1}
def ami2dic(ami):
return dict(zip(ami , ami[1:] + [ami[0]]))
def amis2dics(amis):
return [dict(zip(ami , ami[1:] + [ami[0]])) for ami in amis]
# kの辞書dic_aによる行先を返す。辞書にないなら行先はk。
def ami_go(k,dic_a):
return dic_a[k] if k in dic_a.keys() else k
#あみだの辞書a,bの連結をする。
def conL(a,b):#a,bの順に演算する。
keys = list(set(list(a.keys()) + list(b.keys())))
dic ={key:ami_go(ami_go(key,a),b) for key in keys if key !=ami_go(ami_go(key,a),b)}
if len(dic)==0:
dic={1:1}
return dic
def conR(a,b):#b,aの順に演算する。
return conL(b,a)
#アミダを、(辞書,名)のタプルのリストにする。
def rotdic(S,SN):
dic=[ami2dic(x) for x in S]
return list(zip(dic,SN))
# あみだ辞書dic_aを名で返す。
def name(dic_a):
global Nlist
return [item[1] for item in Nlist if item[0]==dic_a][0]
# あみだ辞書集dicsを名のリストで返す。
def names(dics):
global Nlist
return [item[1] for item in Nlist for b in dics if item[0]==b]
# あみだ辞書の集合Hと辞書aを演算した結果リストを返す。
def Ha(H,a):
global Nlist
res=[]
for b in H:
res +=[item[1] for item in Nlist if item[0]==conR(b,a)]
return res
def aH(a,H):
global Nlist
res=[]
for b in H:
res +=[item[1] for item in Nlist if item[0]==conR(a,b)]
return res
#==================================以上が基本関数====================
#群表を作ろう。
def maketable():
global Nlist
G = [x[0] for x in Nlist]
print("*",names(G))
for item in G:
print(name(item),aH(item,G))
return True
e=[1]
s=[1,2,3]
r=[1,3,2]
b=[1,2]
c=[1,3]
a=[2,3]
S=[e,r,s,a,b,c]
SN=["e","r","s","a","b","c"]
Nlist=rotdic(S,SN)
#=================================以上が今回の前準備==================
maketable()
#================================================================
[OUT]
* ['e', 'r', 's', 'a', 'b', 'c']
e ['e', 'r', 's', 'a', 'b', 'c']
r ['r', 's', 'e', 'c', 'a', 'b']
s ['s', 'e', 'r', 'b', 'c', 'a']
a ['a', 'b', 'c', 'e', 'r', 's']
b ['b', 'c', 'a', 's', 'e', 'r']
c ['c', 'a', 'b', 'r', 's', 'e']
++記号の演習
<数学の抽象化は概念化と切り離せない>
数学の抽象化は概念化、
つまり「用語と記号」の「約束」の世界だ。
群の「約束記号と用語」になれるために、群の例を記号・用語で確認する演習をしたい人はどうぞ。
<2項演算*>
2要素x,y∈Sに対する2項演算の結果を中置型でx*yとかくことが多い。四則演算+,-,×,÷なども
もちろん2項演算だ。群は集合の要素に対する2項演算について条件を満たすものにつけたラベルだ。
集合S上の2項演算はxとyの対に対して値zを返す写像fとみることができる。
x,yの順序対は(x,y)とかき、これを要素とするのは直積[Direct Product]集合S×Sだ。
だから、2項演算*のことを
f:S×S→S ; (x,y)→f(x,y)と表記すると、f(x,y)=x*yということになるね。
<群のようなものと群>
「集合」は、入る要素が内包的か外延的な定義などにより決まるもので、空集合∅も集合。
「亜群」は、2項演算で閉じている集合。
「半群」(semigroup)は、閉じているのと結合[associative[法則が言える集合。
「単位的半群,モノイド」(monoid)は、閉じていて結合法則が言えて、単位元eが1つだけある集合。
「群」(group)は閉じていて、結合法則が言えて、単位元が唯一あり、
さらに、xの逆元inverse xが1つずつある集合。単位元しかない群、単位群{e}も群だね。e*e=e。
「アーベル群、可換群」は、群Gの任意の要素についてxy=yxが成り立つもの。
「群の位数」は、群Gの要素数で、#Gとか|G|とかく。
「要素の位数」は、群Gの要素gがg*n=eとなる最小のnをgの位数という。ord(g)=nとかく。
N10={1,2,3,4,5,6,7,8,9,10}とするとき、次の集合はどれか?
(例)a*b=最大公約数(a,b)を求める演算*とすると、(N10,*)は半群。
なぜなら、最大公約数はどれをさきに結合しても同じになるので、結合法則は成り立つ。
しかし、a*e=aとなる単位元eがあるとしたらすべての数の最小公倍数だから、そんなものはない。
(例)a*b=min(a,b)とすると、(N10,*)はモノイド。
なぜなら、minはどのからさきに調べても最後は同じ1つが返るから、結合法則は成り立つ。
また、min(x,10)=x, min(10,10)=10となる。だから10が単位元だからモノイド。どのxについてもmin(x,y)=10となるyは存在するとは限らないから、必ずしも逆元はないので群になれない。
(例)G={X |X= , a2+b2>0, a,b∈R} で(G,・)は群といえる。・は行列の積。
行列の積は一般に交換法則は成り立つとは限らないが、結合法則は成り立つから、半群。
X・E=XとなるEはa=1,b=0とすると、E∈Gだから、単位元は1つだけあり、単位的半群。
X・Y=EとなるYがどんなXにも1つずつあるか?det(X)=k=a2+b2>0だから、逆行列が決まる。
位数について
(例)#S3=3!=6。|S3|=6。
(例)あみだくじの演算*はつなぐことだった。
a*a=e, b*b=e, c*c=e、つまり、a2=b2=c2=eだから、a,b,cの位数は2。
r*r*r=e, s*s*s=e、つまり、r3=s3=eだから、r,sの位数は3。