連結グラフと一筆書き
1.道の長さ
このワークシートはMath by Codeの一部です。
いままではのつながりは、となりあう点と点、辺と辺、点と辺についてだった。
それが、隣接や接続という言葉を使って表されてきた。
これからは隣接していない点と点をつなぐ道を散歩することで、連結しているかどうかを調べてみよう。
グラフGの頂点をn個取り出したとき、そこが辺でつながっていることがある。
始点uから終点vまでのn+1個の点を順にn本の辺でつなぐ1本道を長さnの道uvといいます。
2.連結グラフ
グラフGの2頂点uvに道uvがあるときuvは連結しているといい、これがGのどの2頂点でも言えるときに
Gは連結グラフだという。
2点の連結成分は、辺と両端の2点というのは簡単にわかる。
3点の連結成分は、もとのグラフの部分グラフなので、L字型か三角形かはもとのグラフによる。
4点の連結成分も、もとのグラフの点が誘導する部分グラフにする。
紛らわしいが、孤立点があるときは、1点だけで連結成分という。
ということは、連結成分がいくつもあるということはグラフがバラバラになっていることになる。
連結成分数が1というのはグラフ全体が連結グラフだということだね。
質問:連結グラフかどうかを見た目ではなくデータで判断するにはどうしますか?
頂点数v, 辺数eから適当にグラフを作る関数gene_G(v,e)を作ります。
隣接行列の0乗からnー1乗までの和を求める関数walkSum(隣接行列)を作ります。
これから各頂点数から散歩する道順数の合計がわかるので、0でないなら1に直して連結行列でできる。
その行列を1次元にフラット化して、0が1つもないなら連結グラフだと判定しましょう。
#[IN]Python
#========================================
import networkx as nx
import random
import numpy as np
def walkSum(A):
n = len(A)
res = np.identity(n) # 道順数行列 (初期化 by 単位行列 )
M = np.identity(n) # 散歩行列
for i in range(1,n): # 各点からn-1回散歩する。
# 散歩の長さを増やすたびに、散歩行列を更新し、道順数行列に足し込む
M= M @ A
res = res + M
return res
def gene_G(v,e):
# 頂点数v,辺数eのグラフをデタラメに作り、隣接行列Aと、グラフGを返す
A=[[0]*v for i in range(v)] # v*vの隣接行列 (初期化 by 0 )
nodes = [x for x in range(v)] # 0〜v-1のv個の点
edges = [] # ランダムにできる辺
G = nx.Graph()
while len(edges) < e:
i,j = random.sample(range(v),2)
if i > j: i,j = j,i
edges.append((i,j)) #辺の格納
A[i][j] = A[j][i]= 1 #隣接行列の更新(by 1)
#グラフオブジェクトに辺と点を一括で登録する
G.add_edges_from(edges)
G.add_nodes_from(nodes)
return A,G
#==========上が関数、下がやりたいこと=======
Vs=10
Es=15
A,G = gene_G(Vs,Es)
nx.draw_networkx(G)
B = np.where(walkSum(A)>=1,1,0) #道順数が0でないなら1にして連結行列とする。
all(B.flatten()) #連結グラフならTrue
#=========================================
[OUT]
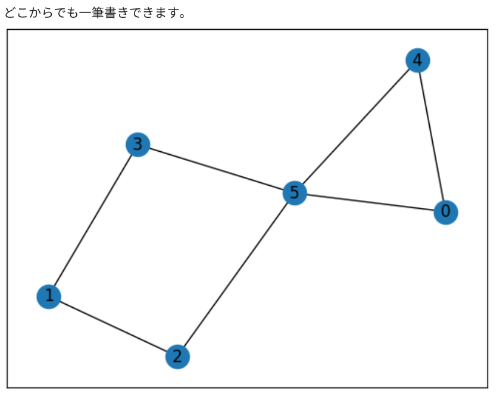
3.一筆書き
連結グラフは、一筆書きができるかもしれない。
頂点の次数がどれも偶数(偶点)ならば、重複なく全辺を通る回路、オイラー回路がある。
そのグラフはオイラーグラフといい、一筆書きができるね。
また、次数が奇数の点(奇点)がちょうど2個あるときにオイラー小道(始点と終点が一致するとは限らないが、すべての辺を重複なく通る小道)があるときも、一筆書きができるというよね。
質問:データから一筆書きができるかどうかと描き方を答えるコードはどうかきますか。
たとえば、隣接リストから奇点のリストを出す関数evenPoints()を作りましょう。
連結かどうかを上記と同様に調べ、奇点数に従って、コメントを用意しておきます。
ちなみに、握手定理Gの辺の総数2|E(G)|=Σdeg(v)
から、グラフの次数の総和は偶数になるので、奇点になる頂点はかならず偶数個とわかるね。
#[IN]Python
#=====================================================================
#一筆書き
import networkx as nx
import random
import numpy as np
def walkSum(A):
n = len(A)
res = np.identity(n) # 道順数行列 (初期化 by 単位行列 )
M = np.identity(n) # 散歩行列
for i in range(1,n): # 各点からn-1回散歩する。
# 散歩の長さを増やすたびに、散歩行列を更新し、道順数行列に足し込む
M= M @ A
res = res + M
return res
def evenPoints(A):
n = len(A)
nodes = [x for x in range(n)] # 0〜n-1のn個の点
rsum = np.sum(A, axis=1) # 行ごとの合計リストを作る。
even_map = list(map(lambda x: x % 2 ==0 , rsum)) #ノードが偶点ならTrue、奇点ならFalse
odd_points =[x[0] for x in zip(nodes,even_map) if x[1]==False] #奇点のノードだけ取りしたリスト
return odd_points
def gene_G(v,e):
# 頂点数v,辺数eのグラフをデタラメに作り、隣接行列Aと、グラフGを返す
A=[[0]*v for i in range(v)] # v*vの隣接行列 (初期化 by 0 )
nodes = [x for x in range(v)] # 0〜v-1のv個の点
edges = [] # ランダムにできる辺
G = nx.Graph()
while len(edges) < e:
i,j = random.sample(range(v),2)
if i > j: i,j = j,i
edges.append((i,j)) #辺の格納
A[i][j] = A[j][i]= 1 #隣接行列の更新(by 1)
#グラフオブジェクトに辺と点を一括で登録する
G.add_edges_from(edges)
G.add_nodes_from(nodes)
return A,G
#==========上が関数、下がやりたいこと=======
Vs=6
Es=10
A,G = gene_G(Vs,Es)
Euler = evenPoints(A) #奇点のリスト
Connect = all(np.where(walkSum(A)>=1,1,0).flatten()) #連結グラフならTrue
nx.draw_networkx(G)
if Connect == True:
if len(Euler)==0:#奇点が0個
msg='どこからでも一筆書きできます。'
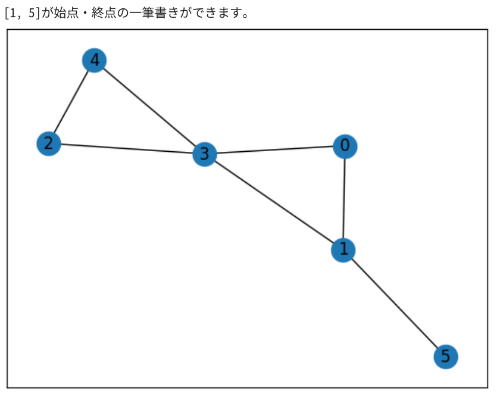
elif len(Euler)==2:#奇点が2個
msg=str(Euler)+ 'が始点・終点の一筆書きができます。'
else:
msg='奇点が' + str(Euler) + 'の' + str(len(Euler))+'個あるため、'
msg +='連結グラフですが一筆書きできません'
else:
msg='グラフが連結ではありません。'
print(msg)
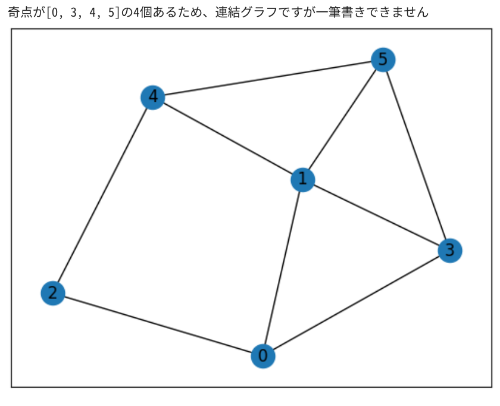
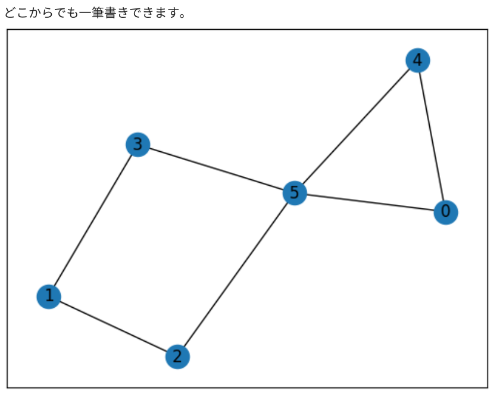
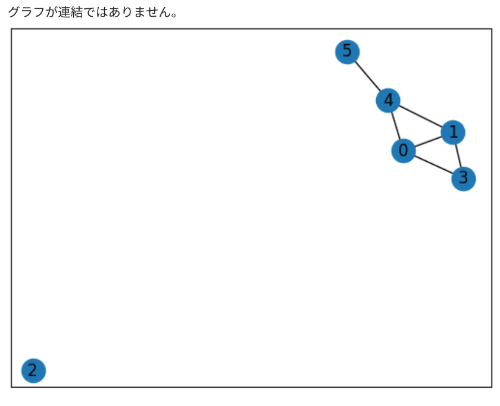
4。一筆書きの比率
適当なグラフをかくと、オイラーグラフになることは少ないけれど、奇点が2個ある連結グラフができて、一筆書きができることは多い。
質問:そこで、その感覚が正しいのか、どのくらいの比率なのか、頂点と辺の数の変化がその比率に影響する傾向があるか。
連結グラフで奇点が0個、連結グラフで奇数が2個、連結グラフで奇数点が2個より多い、非連結グラフ
この4タイプの比率を調べてみよう。
グラフ作成関数が隣接グラフだけを返すように変更した上で、
調査のための関数を作ろう。
頂点の数をv=6から10まで変えてみる。
辺の数eは連結可能な最小数v-1から完全グラフになれるv(v-1)/2まで変えてみよう。
def gene_G(v,e):
# 頂点数v,辺数eのグラフをデタラメに作り、隣接行列Aと、グラフGを返す
A=[[0]*v for i in range(v)] # v*vの隣接行列 (初期化 by 0 )
nodes = [x for x in range(v)] # 0〜v-1のv個の点
edges = [] # ランダムにできる辺
G = nx.Graph()
while len(edges) < e:
i,j = random.sample(range(v),2)
if i > j: i,j = j,i
edges.append((i,j)) #辺の格納
A[i][j] = A[j][i]= 1 #隣接行列の更新(by 1)
#グラフオブジェクトに辺と点を一括で登録する
return A
#==========次は調査のための関数=======
def statEuler(v,e,trials):
res=[0,0,0,0]
for i in range(trials):
A = gene_G(v, e) #隣接グラフのみ
Euler = evenPoints(A) #奇点のリスト
Connect = all(np.where(walkSum(A)>=1,1,0).flatten()) #連結グラフならTrue
if Connect == True:
if len(Euler)==0:
res[0] +=1
elif len(Euler)==2:
res[1] +=1
else:
res[2] +=1
else:
res[3] +=1
return [ res[0]/trials, res[1]/trials, res[2]/trials, res[3]/trials]
def test1(minV, maxV):
trialCount = 100
result =[]
for V in range(minV,maxV):
F = int(V*(V-1)/2)
for E in range(V-1,F+1):
result.append([V, statEuler(V, E, trialCount)])
return result
print("test1の結果==================")
test1(6,10)
#======================================================
[OUT]
test1の結果==================
[[(6, 5), [0.02, 0.47, 0.37, 0.14]],
[(6, 6), [0.03, 0.4, 0.5, 0.07]],
[(6, 7), [0.02, 0.39, 0.48, 0.11]],
[(6, 8), [0.01, 0.41, 0.51, 0.07]],
[(6, 9), [0.03, 0.48, 0.37, 0.12]],
[(6, 10), [0.02, 0.43, 0.49, 0.06]],
[(6, 11), [0.02, 0.38, 0.5, 0.1]],
[(6, 12), [0.03, 0.42, 0.45, 0.1]],
[(6, 13), [0.02, 0.49, 0.44, 0.05]],
[(6, 14), [0.01, 0.41, 0.42, 0.16]],
[(6, 15), [0.05, 0.42, 0.43, 0.1]],
[(7, 6), [0.04, 0.41, 0.43, 0.12]],
[(7, 7), [0.04, 0.4, 0.45, 0.11]],
[(7, 8), [0.01, 0.49, 0.43, 0.07]],
[(7, 9), [0.04, 0.42, 0.45, 0.09]],
[(7, 10), [0.03, 0.5, 0.34, 0.13]],
[(7, 11), [0.03, 0.43, 0.45, 0.09]],
[(7, 12), [0.06, 0.38, 0.46, 0.1]],
[(7, 13), [0.02, 0.46, 0.43, 0.09]],
[(7, 14), [0.0, 0.44, 0.44, 0.12]],
[(7, 15), [0.03, 0.38, 0.48, 0.11]],
[(7, 16), [0.02, 0.38, 0.43, 0.17]],
[(7, 17), [0.02, 0.45, 0.4, 0.13]],
[(7, 18), [0.02, 0.44, 0.41, 0.13]],
[(7, 19), [0.03, 0.44, 0.44, 0.09]],
[(7, 20), [0.02, 0.39, 0.47, 0.12]],
[(7, 21), [0.04, 0.34, 0.53, 0.09]],
[(8, 7), [0.02, 0.36, 0.52, 0.1]],
[(8, 8), [0.02, 0.34, 0.52, 0.12]],
[(8, 9), [0.01, 0.47, 0.43, 0.09]],
[(8, 10), [0.0, 0.43, 0.41, 0.16]],
[(8, 11), [0.03, 0.47, 0.45, 0.05]],
[(8, 12), [0.04, 0.4, 0.46, 0.1]],
[(8, 13), [0.04, 0.42, 0.4, 0.14]],
[(8, 14), [0.03, 0.41, 0.49, 0.07]],
[(8, 15), [0.02, 0.45, 0.34, 0.19]],
[(8, 16), [0.0, 0.32, 0.55, 0.13]],
[(8, 17), [0.01, 0.42, 0.47, 0.1]],
[(8, 18), [0.02, 0.48, 0.39, 0.11]],
[(8, 19), [0.04, 0.39, 0.5, 0.07]],
[(8, 20), [0.02, 0.41, 0.41, 0.16]],
[(8, 21), [0.02, 0.35, 0.55, 0.08]],
[(8, 22), [0.01, 0.38, 0.53, 0.08]],
[(8, 23), [0.02, 0.4, 0.47, 0.11]],
[(8, 24), [0.03, 0.41, 0.46, 0.1]],
[(8, 25), [0.02, 0.44, 0.49, 0.05]],
[(8, 26), [0.03, 0.37, 0.49, 0.11]],
[(8, 27), [0.03, 0.41, 0.43, 0.13]],
[(8, 28), [0.04, 0.34, 0.51, 0.11]],
[(9, 8), [0.01, 0.39, 0.52, 0.08]],
[(9, 9), [0.03, 0.38, 0.46, 0.13]],
[(9, 10), [0.02, 0.38, 0.52, 0.08]],
[(9, 11), [0.01, 0.44, 0.41, 0.14]],
[(9, 12), [0.02, 0.49, 0.4, 0.09]],
[(9, 13), [0.01, 0.37, 0.51, 0.11]],
[(9, 14), [0.02, 0.41, 0.47, 0.1]],
[(9, 15), [0.02, 0.31, 0.57, 0.1]],
[(9, 16), [0.04, 0.47, 0.39, 0.1]],
[(9, 17), [0.01, 0.43, 0.48, 0.08]],
[(9, 18), [0.01, 0.51, 0.4, 0.08]],
[(9, 19), [0.03, 0.33, 0.56, 0.08]],
[(9, 20), [0.0, 0.39, 0.47, 0.14]],
[(9, 21), [0.01, 0.38, 0.47, 0.14]],
[(9, 22), [0.01, 0.46, 0.46, 0.07]],
[(9, 23), [0.04, 0.36, 0.53, 0.07]],
[(9, 24), [0.03, 0.42, 0.42, 0.13]],
[(9, 25), [0.02, 0.4, 0.51, 0.07]],
[(9, 26), [0.01, 0.4, 0.47, 0.12]],
[(9, 27), [0.01, 0.28, 0.55, 0.16]],
[(9, 28), [0.01, 0.48, 0.38, 0.13]],
[(9, 29), [0.03, 0.38, 0.46, 0.13]],
[(9, 30), [0.04, 0.44, 0.44, 0.08]],
[(9, 31), [0.03, 0.39, 0.45, 0.13]],
[(9, 32), [0.05, 0.32, 0.52, 0.11]],
[(9, 33), [0.03, 0.41, 0.42, 0.14]],
[(9, 34), [0.04, 0.44, 0.39, 0.13]],
[(9, 35), [0.01, 0.41, 0.5, 0.08]],
[(9, 36), [0.03, 0.3, 0.55, 0.12]]]
あまり、V,Eの変動にようる比率の変化は見られない。
そこで、比率を平均値を求めてみよう。
def test2(minV, maxV):
trialCount = 100
result =[]
for V in range(minV,maxV):
F = int(V*(V-1)/2)
for E in range(V-1,F+1):
result.append(statEuler(V, E, trialCount))
a=sum(list(map(lambda x:x[0], result)))/len(result)
b=sum(list(map(lambda x:x[1], result)))/len(result)
c=sum(list(map(lambda x:x[2], result)))/len(result)
d=sum(list(map(lambda x:x[3], result)))/len(result)
return a,b,c,d
print("test2の結果==================")
test2(6,10)
test2の結果==================
[258]:
(0.02564102564102564,
0.4030769230769231,
0.47038461538461535,
0.1008974358974359)
一筆書きできるのが約43%、できないのが約57%という比率はおもしろ比率だね。
どこからでも一筆書きできるオイラーグラフは2.5%とわりとレアな感じが比率に表れている。