dfsでhamiltonPathをめざす
このワークシートはMath by Codeの一部です。
treeで遊ぼうでは、
木の頂点を親からスタートしてすべてなぞる(traverse)とき
前置、中置、後置という3種類の順番があることを知った。
また、探索するには深さ優先と幅優先があることも知ったね。
今回は、木ではなくグラフで、
なぞる1方法、深さ優先検索、
DepthFirstSearch, DFSに挑戦してみよう。
<隣接のデータ化>
dfsを木からグラフに一般化する前に隣接関係をみてみよう。
点と点が辺でつながっていること、隣接(adjacent)していることを、どう表しますか。
例えば、V=['a','b','c','d']、E=[('a','b'),('a','c'),('a','d'),('b','c'),('c','d')]のグラフがあるとしよう。
隣接点セットのリストというやり方が思いつくね。
Vの要素xの隣接点セット、近傍N(x)を並べたリストだ。
[{'b','c','d'}, # N('a')
{'a'}, #N('b')
{'a','b'}, #N('c')
{'a','c'} #N('d')
]
注意点は頂点a,b,c,dが集合ではなく、リストとして順番を持たせないと、参照がしにくいということだ。
アクセスしやすさを考えて、頂点をキーにした隣接点辞書にする方法があります。
{"a":set("bcd"), "b":set("a"), "c":set("ab"),"d":set("ac")}
コメントも不要になりますね。
頂点Vの数が4だから、4×4の行列にして、インデックスをa,b,c,dの順に0,1,2,3とすることで、i行j列に
1を立てると連結、0だと非連結とする隣接行列にすることで、行列操作でグラフを扱うという方向性
に進むこともありますね。
1.スタートとゴールを決めて探索する
<深さ優先の考え方>
dfsの考え方はわりと簡単で、訪問した点には印をつけておき、
同じ点をくり返し訪問しないようにする。
だから、簡単にかくと、次のような関数になるね。
dfs(u):
1.もし、頂点uが訪問済なら終了する。
2.そうでないなら、uをたどる。
・uは訪問済みに変更する。
・uのすべての隣接点vについて、dfs(v)をする。ここで1つ深く進むことになる。
しかし、よく考えると問題がある。
訪問して行き止まりになったら、さっきいた点は訪問済だから、もとに戻れなくなる。
だから、同じ深さの探索のレベル上では、再帰で進んだあとの行に、訪問済をキャンセルする操作、
つまり、バックトラック(戻り道)しないと、行き止まりでループしたり、終了してしまう。
バックトラックというと、難しそうに感じるひともいるかもしれない。
でも、これって、迷路で行き止まりになりそうなときは、
壁の左がわをさわって進むと同じところに戻ることで、行き止まりからの復帰、
戻り道をしているのと同じイメージだね。
だから、
dfs(u):
1.もし、頂点uが訪問済なら終了する。
2.そうでないなら、uをたどる。
・uを訪問済にする
・uのすべての隣接点vについて、dfs(v)をする
3.uの探索が終わっているから、uを未訪問とする。
質問:dfsの考え方でグラフの中のpathをさがすにはどうしたらよいでしょうか。
pathのstartとendを与え、グラフ構造としてのデータgraphを与えます。
グラフの各点の訪問済かどうかの記録用の辞書visitedも与えます。
また、記録用にpathというリストを参照型で与えましょう。
だから、dfsの引数はgraph, start,end,visited,pathで、戻り値はresultです。
dfsは
1。探索の現在地now_posでの訪問記録に印をつけてpathに追記する。
2。現在地がendについたらpathを返して終了。
3。隣接点neighborが訪問済でないなら、深くdfsを再帰的に進む。
4。now_pos探索後は訪問記録vの印を消しpathも1つ消し。無しを返す。
入口用の関数find_path(graph,start,end)を作り、dfsが動くために
graphという辞書から、訪問記録として辞書を初期化します。
たとえば、
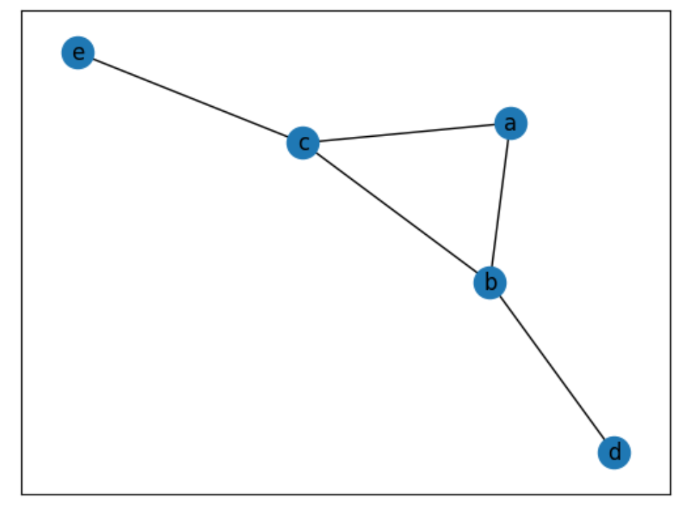
graph = {
"a": ["b", "c"],
"b": ["a", "c", "d"],
"c": ["a", "b", "e"],
"d": ["b"],
"e": ["c"]
}
というグラフでは、dfs(a)→dfs(b)でpathにa,bが順調につまれます。
ところが、bの辞書の先頭のaは訪問済だから、dfs(c)に進み、path=[a,b,c]となります。
次にcの辞書のa,bが訪問済なので、dfs(e)に進み、paht=[a,b,c,e]となりますね。
現在地==endなので、このpathを返します。
このプログラムの特徴は、
最短経路を探しているわけではないし、一つ見つかれば終了します。
複数見つけることはできませんし、最短でもないのですが、迷路図をデータ化して抜け出す方法を見つけたりするには使えそうですね。
[IN]Python
#================================================
import networkx as nx
from collections import defaultdict
from matplotlib import pyplot as plt
#ここからPathの検索(深さ優先)
def dfs(graph, now_pos, goal, visited, path):
visited[now_pos] = True
path.append(now_pos)
if now_pos == goal:
return path
for neighbor in graph[now_pos]:
if not visited[neighbor]:
result = dfs(graph, neighbor, goal, visited, path.copy())
if result:
return result
visited[now_pos] = False
path.pop()
return None
def find_path(graph, start, end):
keys=graph.keys()
visited={}
for item in keys:
visited[item]=False
path = []
return dfs(graph, start, end, visited, path)
def solve_path(graph,start,end):
#グラフ
G = nx.Graph()
nodes = graph.keys()
edges = []
G.add_nodes_from(nodes)
for k,v in graph.items():
for vi in v:
edges.append((k,vi))
G.add_edges_from(edges)
pos = nx.circular_layout(G)
nx.draw_networkx(G)
#探索開始
result = find_path(graph, start,end)
print(result)
if result:
arrowList=[]
answer = f"見つかったpathは{result[0]}"
for i in range(len(result)-1):
arrowList.append((result[i],result[i+1]))
answer +=f"->{result[i+1]}"
else:
answer="パスは見つかりませんでした"
return answer
# グラフデータと実行
graph = {
"a": ["b", "c"],
"b": ["a", "c", "d"],
"c": ["a", "b", "e"],
"d": ["b"],
"e": ["c"]
}
start = "a"
end = "e"
solve_path(graph,start,end)
#=====================================================
[OUT]
['a', 'b', 'c', 'e']
'見つかったpathはa->b->c->e'
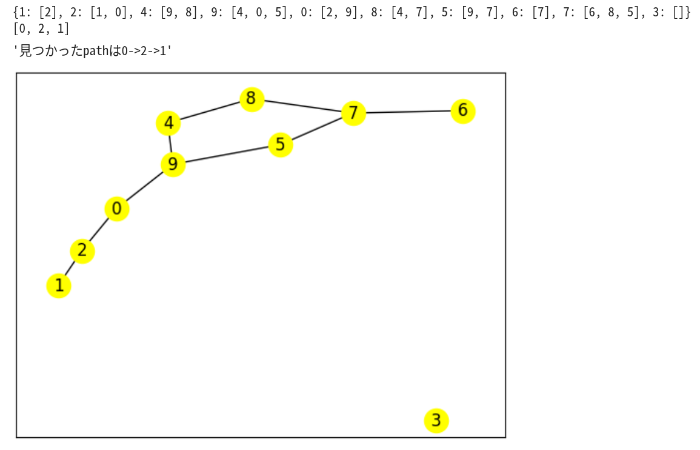
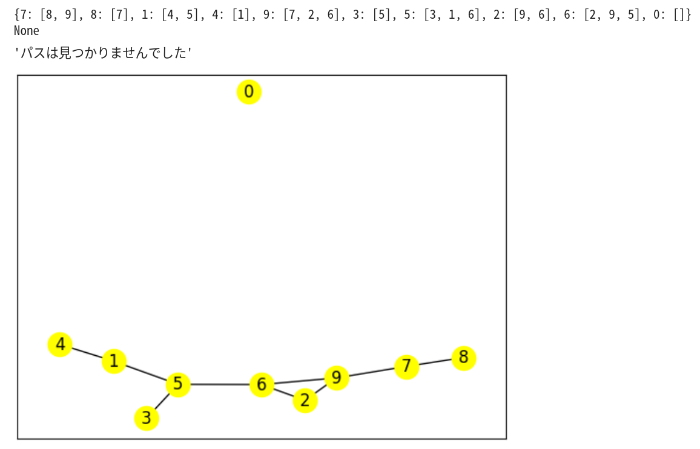
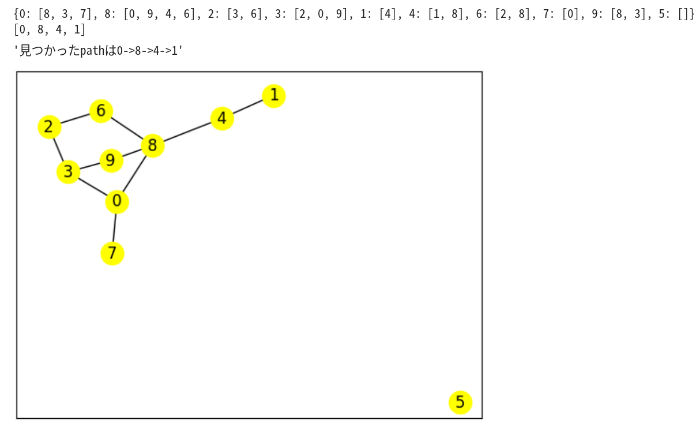
適当なグラフを生成して実験してみよう。
頂点数,辺数ともに10として、0から1へのpathを探す。
Vs=10
Es=10
start=0
goal=1
ad,G = gene_G(Vs,Es)
solve_path(ad,start,goal)
2.ゴールを決めずにいけるところまで進もう
今度は、ゴールを決めずにいけるところまで進もう。
質問:ゴールを決めないで探索するにはどうしたらようでしょうか。
dfsなどで、endやゴールを取り除きます。また、now_pos==goalならpathを返すというのをやめて、
進めたらそのつどprint(path)をしよう。
#ゴールなし
import networkx as nx
from collections import defaultdict
from matplotlib import pyplot as plt
#ここからPathの検索(深さ優先)
def dfs(graph, now_pos, visited, path):
visited[now_pos] = True
path.append(now_pos)
print(path)
for neighbor in graph[now_pos]:
if not visited[neighbor]:
result = dfs(graph, neighbor, visited, path.copy())
visited[now_pos] = False
path.pop()
return None
def find_path(graph, start):
keys=graph.keys()
visited={}
for item in keys:
visited[item]=False
path = []
return dfs(graph, start, visited, path)
def solve_path(graph,start):
#グラフ
G = nx.Graph()
nodes = graph.keys()
edges = []
G.add_nodes_from(nodes)
for k,v in graph.items():
for vi in v:
edges.append((k,vi))
G.add_edges_from(edges)
pos = nx.circular_layout(G)
nx.draw_networkx(G)
#探索開始
result = find_path(graph, start)
return result
# グラフデータと実行
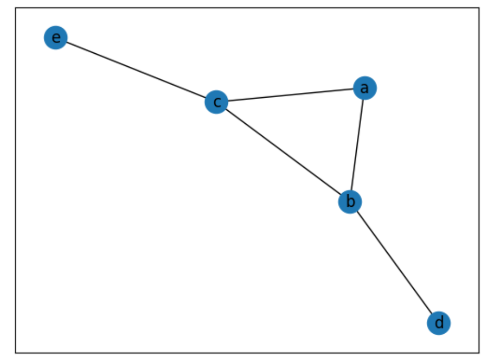
graph = {
"a": ["b", "c"],
"b": ["a", "c", "d"],
"c": ["a", "b", "e"],
"d": ["b"],
"e": ["c"]
}
start = "a"
solve_path(graph,start)
#================================
[OUT]
['a']
['a', 'b']
['a', 'b', 'c']
['a', 'b', 'c', 'e']
['a', 'b', 'd']
['a', 'c']
['a', 'c', 'b']
['a', 'c', 'b', 'd']
['a', 'c', 'e']
3。ハミルトンパスが見つかるかも
スタートもゴールも決めずに調べて、
もし全点通過するパスができたら、それはハミルトンパスと言われているね。
それをめざして取り組んでみよう。
スタートを中で回して、パスを共通のところに格納しながらあとで、
その経路の通過頂点数がグラフの頂点数と同じになればハミルトンパスといえるね。
質問:パスを記録しながら最長のパスを表示するにはどんな工夫が必要でしょうか。
深さ優先のために、dfs関数でどんどん進むがこれ以上すすめなくなったときに
最長パスになる可能性がある。
だから、むしろ進めなくなったときに作った最長パスpathをprevpathに保存しておくことで、
pathの記録リストpathsに記録できる。dfsに入ったときも、これ以上進めなくなった状態でも,
重複をかまわず記録漏れをなくすことを優先してpathsにためこもう。
dfsの依頼主であるfind_pathにpathsを返すと、たまったpathの最長値maxlenを記録し、
maxlenにあてはまる最長のリストを依頼主hamilton_pathに返そう。
hamilton_pathはnodesの頂点を順にstartにしながらfind_pathの結果をためこみ、すべての頂点の最長パスを比べて、グラフ全体の最長パスを返します。最後にパスを返す前に重複と取り除き、パスの長さが頂点数と同じになるパスならば、ハミルトンパスというラベルをつけよう。
#すべての点をスタートにしてなぞる。
import networkx as nx
from collections import defaultdict
from matplotlib import pyplot as plt
#ここからPathの検索(深さ優先)
def dfs(graph, now_pos, visited, path,prevpath,paths):
prevpath = path
visited[now_pos] = True
path.append(now_pos)
paths.append(path)
for neighbor in graph[now_pos]:
if not visited[neighbor]:
dfs(graph, neighbor, visited, path.copy(), prevpath.copy(),paths)
else:
paths.append(prevpath.copy())
visited[now_pos] = False
path.pop()
return paths
def find_path(graph, start):
keys=graph.keys()
visited={}
for item in keys:
visited[item]=False
path = []
prevpath = []
paths = []
res = dfs(graph, start, visited, path, prevpath,paths)
maxlen = max(list(map(lambda x:len(x), res)))
fil= list(filter(lambda x:len(x)==maxlen, res))
return fil
def hamilton_path(graph):
#グラフ
G = nx.Graph()
nodes = graph.keys()
edges = []
G.add_nodes_from(nodes)
for k,v in graph.items():
for vi in v:
edges.append((k,vi))
G.add_edges_from(edges)
pos = nx.circular_layout(G)
nx.draw_networkx(G, node_color='yellow')
#探索開始
results =[]
for start in nodes:
result = find_path(graph,start)
for item in result:
results.append(item)
#print(results)
maxlen = max(list(map(lambda x:len(x), results)))
filtered= list(filter(lambda x:len(x) == maxlen, results))
unique_list = []
for item in filtered:
if item not in unique_list:
unique_list.append(item)
for item in unique_list:
if len(item)==len(nodes):
comment ="Hamilton Path:"
else:
comment ="longest Path:"
print(comment,item)
return unique_list
# グラフデータと実行
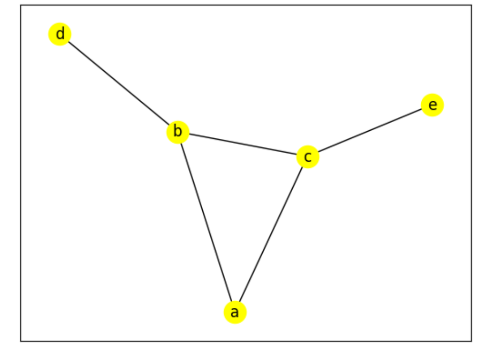
graph = {
"a": ["b", "c"],
"b": ["a", "c", "d"],
"c": ["a", "b", "e"],
"d": ["b"],
"e": ["c"]
}
longest = hamiltorn_path(graph)
#===================================================
[OUT]
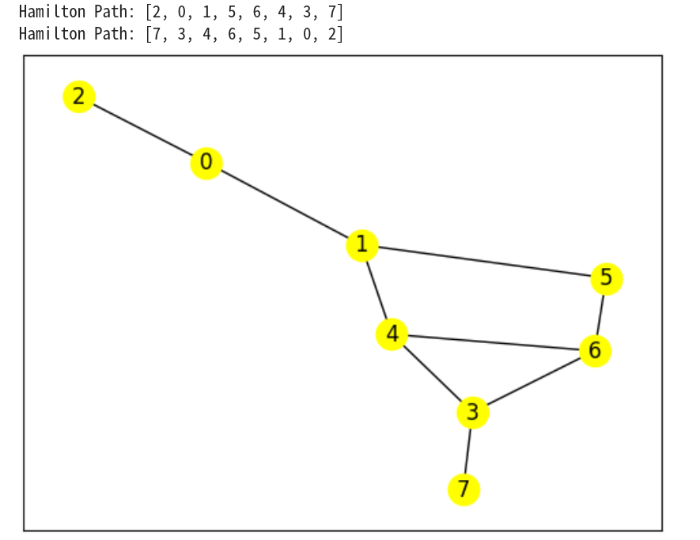
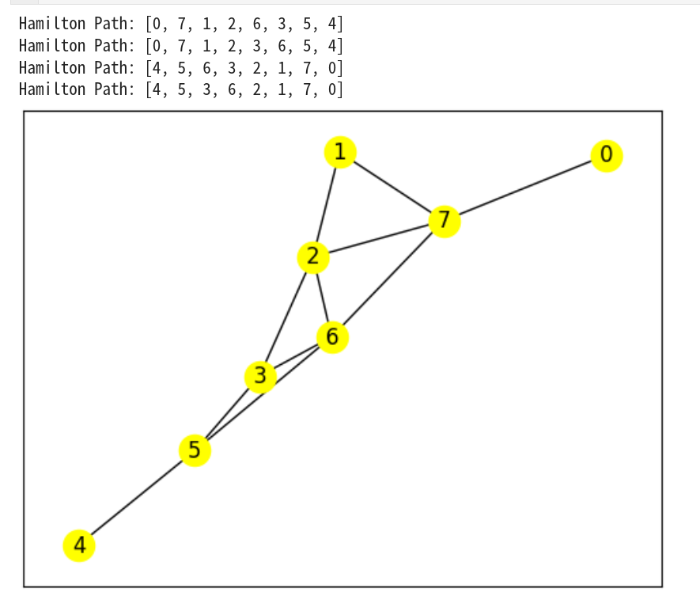
Hamilton Path: ['d', 'b', 'a', 'c', 'e']
Hamilton Path: ['e', 'c', 'a', 'b', 'd']
適当に、連結で多重でない単純なグラフをかいて、ハミルトンパスがあるかを探ろう
#上の続き==============
import networkx as nx
from collections import defaultdict
from matplotlib import pyplot as plt
import random
def gene_G(v,e):
nodes = [x for x in range(v)] # 0〜v-1のv個の点
edges = [] # ランダムにできる辺
G = nx.Graph()
while len(edges) < e:
i,j = random.sample(range(v),2)
if i > j: i,j = j,i
edges.append((i,j)) #辺の格納
G.add_edges_from(edges)
G.add_nodes_from(nodes)
Ad = nx.to_dict_of_lists(G) #隣接辞書
return Ad,G
Vs=8
Es=15
ad,G = gene_G(Vs,Es)
if nx.is_connected(G):
longest = hamiltorn_path(ad)
else:
print("非連結です")