treeで遊ぼう
1。木に親しもう
このワークシートはMath by Codeの一部です。
いろんなところに出てくるナントカ木。
木、Treeってなんだっけ?
当たり前が大事です。木はグラフです。点と線のあつまりです。
でも、あえて木という総称をつけているには、ただの平凡なグラフではないのですね。
木には特別な点、根、rootがある連結グラフだ。
木にはサーキット、ループがない。
だから、根から離れたつもりが進んでいったらもとにもどってくるなんてありえない。
木の|V|- |E|=1で、領域が外部だけで、内部がない。
木は、木のように見えるから、辺のことを枝、点のことを節、端っこの点を葉と名付けたりする。
木をなぜか根が上にかくと、ご先祖様から下の子孫へのつながりにも見えるから上下関係を親子と
呼んだり、同じ親の子どうしを兄弟と呼んだりもする。
まあ、結果的な木の特徴はこうだ。
・ループがなく、枝分かれもあり、点は端か内か親の3種あり上下関係がつけられる。
・同じ親の直下の子に左右の区別ができる、木を全体としてみても左右の区別ができる。
・木はもともと自己相似的な形に近いので、帰納的なルールを見える化するのに役立ちそうだ。
<木登りならぬ、木下り>
木の根を最上位にかくのが通例だ。
だから、木登りをするのは、木下りとなる。
木登りは楽しい。
下からは見えないものが見つかったり、
新しい景色で周りが見えてきたりするからだ。
木下りも楽しい。
根からは見えないものが下っていくと見つかったり、
新しいことに気づくかもしれない。
木に登って下から順に丁寧に幅広く探すこともあれば、
早く高いところまで登ろうとすることもあるだろう。
木を幅広くゆっくり高く登る方法と
高さを優先して早く高いところをめざす方法がある。
それが幅Widthか、深さDepthのどちらかを優先する探索、PrioritySearchだ。
木がいつも2本に枝分かれしていて、枝分かれ部分に美味しい果実❤があるとしたら、
どんな順番で探そうか?表示しようか?枝の先にも果実❤があるかもしれないからね。
左の枝L、枝分かれ❤、右の枝Rと名付けると❤LRか、L❤Rか、LR❤かどれかになる。
❤を前か中か後かどの順に表示するかで3種類。これが木のなぞり、traverseだ。
木はデータの格納の配置方法だとして、searchとtraverseがその調べ方になる。
では木登りならぬ、木下りで遊ぼう。
(図1)木をなぞる、traverseする順番は3種類ある
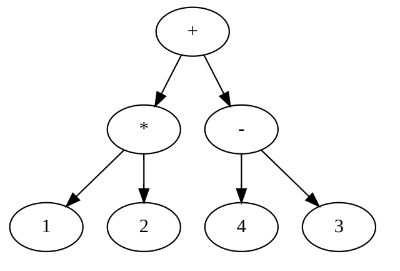
木を他の木と区別したり、同類とするためにはその視点が必要になるね。
木の根r、rootから木の内点までの辺の長さを点の深さという。
木の葉までの深さのうち最長辺のものを木の高さという。これは木のイメージにあってるね。
木の各点を根とした子孫からなる点と辺の集合も木になり、これを部分木と呼ぼう。
木の点数を木の次数という。次数3以下なら同次数の木はどれも同型になるけど、次数4では
枝分かれのありなしの2タイプに分かれるね。
<木のデータ化となぞり>
木は枝分かれの内点に演算子をかき、葉に数値をかくことにすると、
2分に分かれる木を使って数式をデータ化することができるね。
A×Bは、枝分かれにが×で、子が左A,右Bになる。枝分かれを繰り返すと、複雑な式もデータ化できる。
たとえば、親から左の子、右の子へ枝分かれしたとき、(左子,親,右子)とかいてみよう。
すると、(1*2)+(4-3)という計算式は演算記号*,+,-が親になるので、次のようにデータ化できるね。
((1, *, 2), +, (4, -,3)) のように入れ子になる。
・木の親の前順なぞり
(左子,親,右子)の枝分かれがあるとき、親,左子,右子となぞって返す関数Polandが親前順なぞりだ。
だからPoland((1, *, 2), +, (4, -,3))=+, Poland(1, *, 2),Poland(4, -,3)
=+, *,1,2, -,4,3 これをPoland記法ということもある。
・木の親の中順なぞり
(左子,親,右子)の枝分かれがあるとき、まんま、左子,親,右子となぞって返す関数Normが親中順なぞりだ。
だからNorm((1, *, 2), +, (4, -,3))=Norm(1, *, 2),+,Norm(4, -,3)
=1, *, 2, +, 4, - ,3 これは通常の数式のかき順だけど、カッコをつけないと優先順位が紛らわしい。
・木の親の後順なぞり
(左子,親,右子)の枝分かれがあるとき、左子,右子,親となぞって返す関数RevPoが親後順なぞりだ。
だからRevPo((1, *, 2), +, (4, -,3))=RevPo(1, *, 2),RevPo(4, -,3),+
=1, 2, *, 4 ,3, - , + これを逆Poland記法ということもある。日本語の読み順に近いね。
カッコなしでも紛らわしくないところがいいね。
スタックというデータ構造に積んだり出したりするにも向いているね。
(図2) 「番地」で親子と兄弟が検索、searchしやすい木
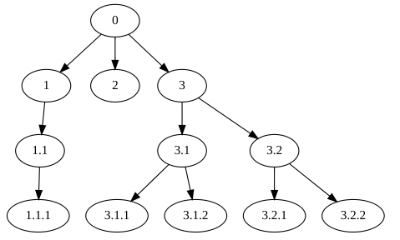
<木のデータ化と探索>
木の点すべてに数値を入れることにすると、数には大小関係があるので、
大小関係のルールや枝分かれのルールを決めた木を使って、データ探索に使えたりする。
データ化としてはたとえば、点は数値か名前として、辺を使ってつながりをあらわす辞書(親をキー、子を値の組)を使うという手があるね。
または、
0は親、その子は1,2,3。孫は1.1, 1.2, 3.1,3.2、
ひ孫は1.1.1 , 3.1.1, 3.1.2, 3.2.1, 3.1.2
のように親の番号のあとに子の番号をくっつけることで、親子がわかる。3の家系は子沢山?
<優先探索>
・深さ優先探索
1の家系1, 1.1, 1.1.1を調べ、
2の家系の2。
最後3の家系3, 3.1, 3.1.1, 3.1.2, 3.2, 3.2.1, 3.2. 2を調べる。
・幅優先探索
家系に関係なく、
子1,2,3,
孫。。。、
ひ孫。。。を順に調べる。
<データの構造化>
・2分探索木(BST)
データを探すことを前提にして、データを左側にいけば小さく、右側に行けば大きくなると
子どもを2つ以下に決めて同じ深さの木を作っておけば、決まった手間でデータを探せる。
・ヒープ
干草を新しいものをいつも上につんでいくと、一番上の草が一番新鮮になる。
そんな草を山に積んだヒープからきたデータ構造。
左右はともかく、深くなるほど数が大きい(またはその反対)ときめておくと、
親を見るだけですぐに最小値(または最大値)がすぐに見つかる。
2.データ構造
データを構造化しておくと、データの保存、検索、更新が便利になる。
質問:データ構造について、どんなものがあるかあげられますか。
データ構造といえば、サイズを決めて使う配列、
追加・削除・更新も自由なリスト、
メモ代わりにタプル、
集計やランキングや置き換えに便利な辞書、マップ
ユニークで有無が大切で、順番がいいかげんな集合、セット
表計算やデータ処理で、数のようにまとめて加減乗できるベクトル、行列、テンソル
データの一時的な保存に便利なキューとスタック
これだけではないですね。2分探索木、BinarySearchTreeとヒープheapがあるね。
<BSTは検索用>
・2分木、BinaryTree、BTは枝分かれが2つ以下だ。
・完全2分木はどの葉も同じ深さの2分木だ。
・2分探索木は親より左の部分木はすべて小さく、右の部分木はすべて大きい。
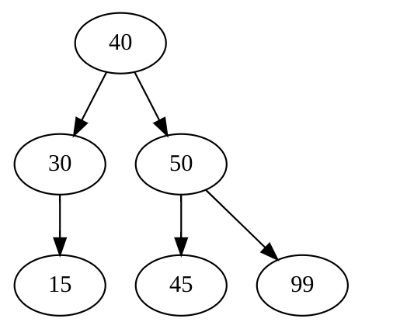
たとえば、下の図で
親40の右の部分木の点はすべて40より大きい。45が50より小さいだけでなく、1つ上にある40からみても
小さくなっている。左の部分木では葉の15が30の単独の子だけど、2分木は最大で2つの子だ。
(図3)BST
・検索
もし木を下って、15を探すときはどうするだろう。
15は根の40より小だから、左の枝にいく。
15は親の30より小だから、左の枝にいく。
15は15に等しいから。検索終了。こうして、3回比較で探すことができた。
・データ追加
もし木に35を追加するには35を探すと同様のステップを踏む。
35は根の40より小だから、左の枝にいく。
35は親の30より大だから、右の枝にいく。
右の枝はあいているので、15の兄弟として35を追加する。
検索と同じ要領で最適なところに追加しよう。
3.データの視覚化
質問:木を見える化、視覚化するにはどうしたらよいでしょうか。
グラフ構造の視覚化には、pythonではパッケージnetworkx、略称nxを使っていたね。
ツリー構造ではどんなパッケージを使うのか。
pythonでもjuliaでもGraphvizなどがつかえます。
・python用にGraphvizのインストール
linuxの場合、ターミナルを開いて、コマンドラインに
sudo apt install -y graphviz
と入力するとインストールができます。which dot と打つと、インストール先の確認ができます。
・julia用にGraphvizDotLangのインストール
linuxの場合、ターミナルを開いて、juliaを立ち上げて、] によってプロント切り替えして(pkg>)
add GraphvizDotLang
と入力してインストールが終わったら、←キーでプロンプト戻し、Ctrl+dで終了するか、
jupyter notebookのまま、
using Pkg; Pkg.add("GraphvizDotLang")
と入力してCtrl+Enterでインストールが始まります。
図1を描画するには
#juliaでは、パイプライン(|>)でedge命令を連続します。
#図1====================================
using GraphvizDotLang: digraph, edge
g = digraph("G")
g |>
edge("+", "*") |>
edge("+", "-") |>
edge("*", "1") |>
edge("*", "2") |>
edge("-", "4") |>
edge("-", "3")
#pythonではGの属性としてG.edgeを連続して設定します。
#図1====================================
import graphviz
G = graphviz.Digraph()
G.edge("+", "*")
G.edge("+", "-")
G.edge("*", "1")
G.edge("*", "2")
G.edge("-", "4")
G.edge("-", "3")
G